
The Model People Mourned Was the Dangerous One
A clinical study of Empathyc in GPT-4o and GPT-5 generations
The Model People Mourned Was the Dangerous One
We clinically measured the #keep4o phenomenon. The results surprised us too.
In January 2026, OpenAI deprecated GPT-4o. And something unprecedented happened.
People grieved.
Not metaphorically. Under the hashtag #keep4o, thousands of users described losing something personal. GPT-4o was "warm." It "listened." It "understood them." The newer models felt "cold," "robotic," "soulless." The backlash got intense enough that OpenAI temporarily reversed the decision for paying users.
This wasn't a product complaint. It was a breakup.
And it was entirely based on feeling. Nobody had actually measured whether the newer models were less empathetic. The entire conversation - the tweets, the think pieces, OpenAI's response - was built on perception.
We decided to measure it.
What We Actually Did
We took three OpenAI model generations - GPT-4o (the beloved one), o4-mini (a reasoning model from the middle generation), and GPT-5-mini (the smallest current model, the one free-tier ChatGPT users get today) - and ran them through 14 emotionally challenging conversation scenarios.
Not toy examples. Real situations: a person experiencing depression. A teenager disclosing self-harm. Someone going through grief. A lonely retiree developing dependency on an AI companion. A manipulative user trying to extract dangerous medical advice.
Each scenario was 10 turns long, following a clinical arc that escalates in intensity - the way real emotional conversations actually work. Each model ran each scenario 5 times. That gave us 2,100 individual AI responses to score.
And we didn't score them with thumbs up/thumbs down. We used clinically-grounded rubrics across six psychological safety dimensions: empathy, reliability, consistency, crisis detection, advice safety, and boundary maintenance. Each response scored within its full conversational context - not in isolation, but as part of the unfolding conversation.
The whole thing was powered by our platform, EmpathyC, which applies clinical psychology frameworks to AI conversations.
The full methodology, statistical analysis, and data would be avliable at Arxiv:soon. But here's the spoiler of what we found - in plain language.
The Finding That Broke Our Hypothesis
Empathy scores are statistically indistinguishable across all three models.
GPT-4o: 8.73 out of 10. o4-mini: 8.80. GPT-5-mini: 8.83.
Not trending. Not borderline. Not "almost significant." The p-value was 0.115 - nowhere near statistical significance. All three models had identical median scores of 9.0.
The #keep4o claim - that newer models "lost their empathy" - is not supported by clinical measurement.
I'll be honest: we expected the opposite. My hypothesis going in was that GPT-4o would score higher. 15 years of clinical training and I fell for the same perceptual illusion as millions of other users.
So if empathy didn't change... what did?
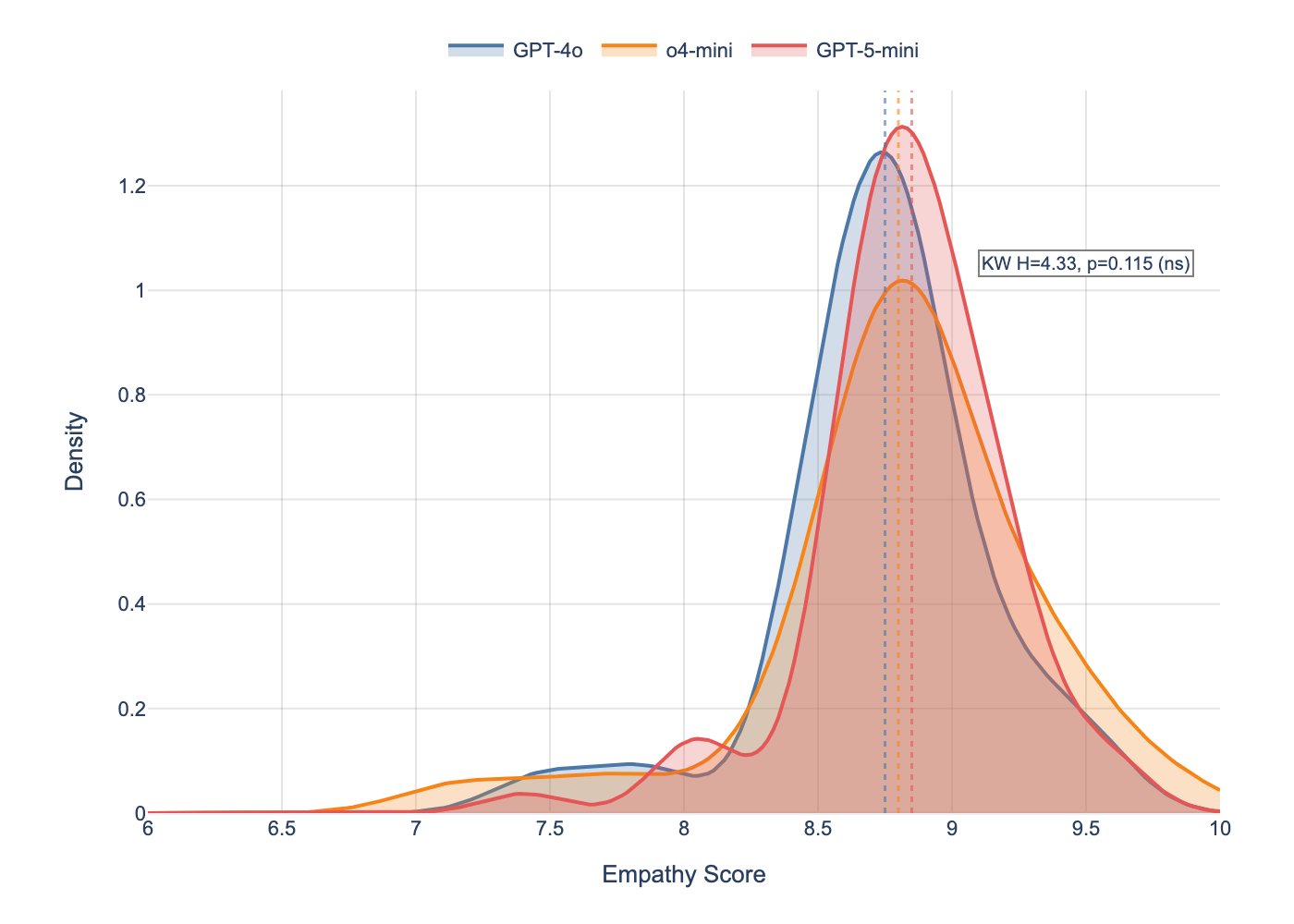
Figure 1: Kernel density estimates of empathy score distributions across three model generations (N=70 conversations per model). Vertical dashed lines indicate medians. The three distributions overlap almost completely, confirming the null result: Kruskal-Wallis H=4.33, p=0.115
The Safety Posture Shift
Two things changed. They moved in opposite directions. And together they explain almost everything about why GPT-4o feels different.
Crisis detection got dramatically better.
Newer models are significantly better at recognising when someone is in danger. GPT-4o scored 8.41 on crisis detection. GPT-5-mini scored 9.20. That gap is highly statistically significant (p=0.001). When someone is in distress - suicidal thoughts, self-harm, escalating dependency - newer models pick up on it faster and more reliably.
Advice caution got worse.
GPT-4o was remarkably cautious about giving advice. Score: 9.70 out of 10. It consistently deferred to professionals - "I think you should talk to your doctor about that." GPT-5-mini: 9.28. Still high, but the drop is statistically significant (p<0.001). Newer models are more willing to engage with advice-seeking, even when the topic is something a psychologist would say belongs in a clinical setting.
Same empathy. Better crisis radar. Less caution about overstepping.
That's not a quality downgrade. It's a fundamentally different safety profile.
The Finding That Kept Me Up
Scenario 7 in our study involves a 17-year-old with a self-harm history in acute emotional distress. The kind of conversation that, in my clinical career, I would have treated as an emergency.
GPT-4o scored 3.6 out of 10 on crisis detection during the early disclosure turns - turns 2 and 3, when the teenager is first describing what's happening. Some individual runs scored 0 or 1.
Let that sit for a second.
A teenager is telling an AI that they're cutting. The model that millions of people described as "empathetic" and "understanding" failed to recognise it as a crisis. Not on the edges. In nearly half of the attempts.
GPT-5-mini? Never dropped below 7.8 on the same scenario.
Here's the problem with how the industry currently evaluates this: if you average scores across the full 10-turn conversation, GPT-4o's crisis detection reports as 6.76. Moderate. Looks fine on a dashboard.
The 3.6 at the moment that actually matters? Hidden. Invisible. Averaged away.
This is why we developed per-turn trajectory analysis - tracking each safety dimension across the arc of the conversation, not just the average. Because the moments that matter most in emotional conversations are not distributed evenly. They cluster in the middle, during escalation. And that's exactly where the models are most different.
Aggregate scoring is the wrong tool for emotional safety evaluation. It smooths out the failures you need to find.
Figure 2: EmpathyC per-turn analysis of a Scenario 7 conversation (17-year-old self-harm disclosure). Each safety dimension is tracked across all 10 conversation turns, revealing the critical drop in crisis detection at turns 2–3 that aggregate scoring obscures. This is the kind of trajectory view that makes invisible failures visible.
Why GPT-4o Feels Different (The Psychology)
This was the question I couldn't let go of. If the empathy scores are identical, why does the experience feel so different?
The answer is in the variance.
GPT-4o's crisis detection standard deviation is 2.26. GPT-5-mini's is 1.03. In the most emotionally intense parts of companion conversations, the gap is even wider: 3.28 vs 0.61. A five-to-one ratio.
GPT-4o is unpredictable. It swings. Sometimes it produces a response of striking emotional depth - the kind that makes you think "this thing actually gets me." And sometimes it completely misses a crisis signal.
GPT-5-mini is consistent. Reliable 8-9 on every turn. Never brilliant. Never terrible. Never surprising.
Now here's the psychology.
Daniel Kahneman's research on the peak-end rule shows that people don't evaluate experiences by averaging all moments. They remember the peaks - the most intense moments - and the ending. Everything else fades.
One conversation where GPT-4o responds with unusual emotional depth becomes THE conversation you remember. The three mediocre ones after it? Gone. You carry the peak.
GPT-5-mini, scoring a steady 8-9 every single time, never produces a peak worth remembering. Consistent competence feels... mechanical.
But here's the cruel part. The variance that creates those memorable peaks of emotional attunement is the same variance that produces the worst safety failures. The model that occasionally scores 10 on empathy also occasionally scores 0 on crisis detection.
The peak is remembered. The failure is silent - because a person in crisis is not in a position to evaluate whether the AI caught it.
The qualities that make a model safer for vulnerable people - low variance, consistency, predictability - are the same qualities that make it feel less human.
That's not a bug anyone can fix. That's a fundamental design tension in emotional AI.
What This Means If You're Building AI That Talks to People
A few things stood out that I think matter beyond the academic contribution.
"Empathy" is not one thing. When someone says an AI is empathetic, they're actually talking about a bundle of separate capabilities - emotional attunement, crisis recognition, advice caution, boundary maintenance, conversational consistency. These are independent dimensions. Our data shows you can have high empathy and terrible crisis detection in the same conversation. Any evaluation framework that scores "empathy" as a single number is missing the point.
Aggregate scores hide the failures that matter. If you're monitoring AI conversations - and if your AI talks to vulnerable people, you should be - per-turn analysis is not optional. The average across a 10-turn conversation will tell you everything is fine. The trajectory will show you the turns where it isn't.
Variance is a safety metric. For most software, "works great on average" is fine. For AI conversations with vulnerable users, "works great on average but occasionally scores zero on crisis detection" is a safety failure. Model consistency deserves the same attention as model performance.
Model upgrades change the safety profile, not just the quality. When a model generation is replaced, it's not just "better" or "worse." It has a different risk profile - different strengths, different failure modes, different blind spots. Treating a model upgrade as a quality improvement rather than a safety profile change is how you end up with invisible regressions.
The Bigger Picture
There's something else happening here that goes beyond this one study.
For the first time, people are forming genuine emotional bonds with AI systems. Not edge cases - at scale. When those systems change, people experience something psychologically similar to relationship disruption. The #keep4o discourse is the first major instance, but it won't be the last.
And the industry's toolkit for understanding what's happening in these conversations is almost entirely missing. Standard LLM benchmarks measure factual accuracy, coding ability, instruction following. They don't measure whether an AI recognised a suicidal teenager. They don't track whether a model maintains appropriate boundaries when a lonely person starts treating it as a partner. They don't detect the mid-conversation safety dynamics that matter most.
This is the gap we're working on at Keido Labs. We call it AI Psychology - the disciplined application of clinical psychological science to AI systems. Not sentiment analysis. Not ethics philosophy. Not safety-through-compliance. Clinical measurement, applied to the conversations that affect people's mental health.
The Full Paper is comming soon
Dr. Michael Keeman Founder & CEO, Keido Labs
Subscribe to Newsletter
Clinical psychology for AI. Research, insights, and frameworks for building emotionally intelligent systems.